
What is a text contextualization?
You’re probably familiar with image recognition, where you take an image and train it to recognize something. When it comes to OCR text, we’re talking about extracting some text from it.
Contextualization in Umango is all about telling the OCR engine how to analyze a region of an image. Telling the engine what to expect increases the accuracy of what we want to extract.
When you look at an area on a document it could be a simple line of text, like a client code or it could be information surrounded with lots of paragraphs, images and tables. Contextualization helps the OCR engine understand what is around the text we are trying to capture.
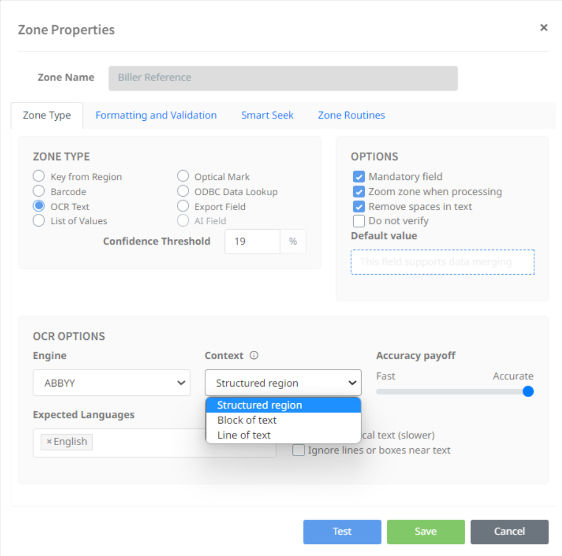
There are three factors that can be adjusted when contextualizing and the setting are:
- Structured region where the zone region we are OCRing may have different types of content including images, boxes, lines, text, shapes and images; all different types of content.
- Block of text one or multiple lines of text where no other content is likely to occur. An example of a block of text is an address field. Block of text is the default type when creating a news zone in a job.
- Line of text where there is one simple line of text with no other content and no carriage returns.
Contextualization tells the OCR engine how to analyze the layout in a region.
Are you interested in learning more about Umango and text contextualization? Contact us at sales@ecoprintq.com to find out more.